The estimates and their confidence intervals should form the basis of your communication. Plotting these conveys the message usually best.
Remark: In frequentist statistics a value of a parameter is fixed, yet unknown. The definition of a 95% confidence interval is that if you would run 100 independent experiments, at least 95 of the obtained confidence intervals are expected to include the true value of the parameter. Bayesian statistics considers a parameter as a random variable with a probability distribution. The bayesian alternative to a 95% confidence interval is called a 95 % credible interval, which is a range which includes 95% of the mass of the posterior probability distribution of the parameter. The latter is what is also what we like to assume about the confidence interval, but is not the case.
Confidence intervals based on fixed models are calculated from the standard errors on the fixed effects. We can do something similar in th case of mixed models to calculate approximate confidence intervals on the estimates of the differences.
A more correct way of calculating the confidence intervals in the case of mixed models is done via profiling of the maximum likelihoods with the function confint.
Check out the documentation for confint() and confint.merMod(). Remember that in R, if you apply confint() on a mixed model (is of class merMod), you apply in reality confint.merMod().
Bringing estimates and confidence intervals and plotting, should become your preferred method to interpret and to convey your conclusions.
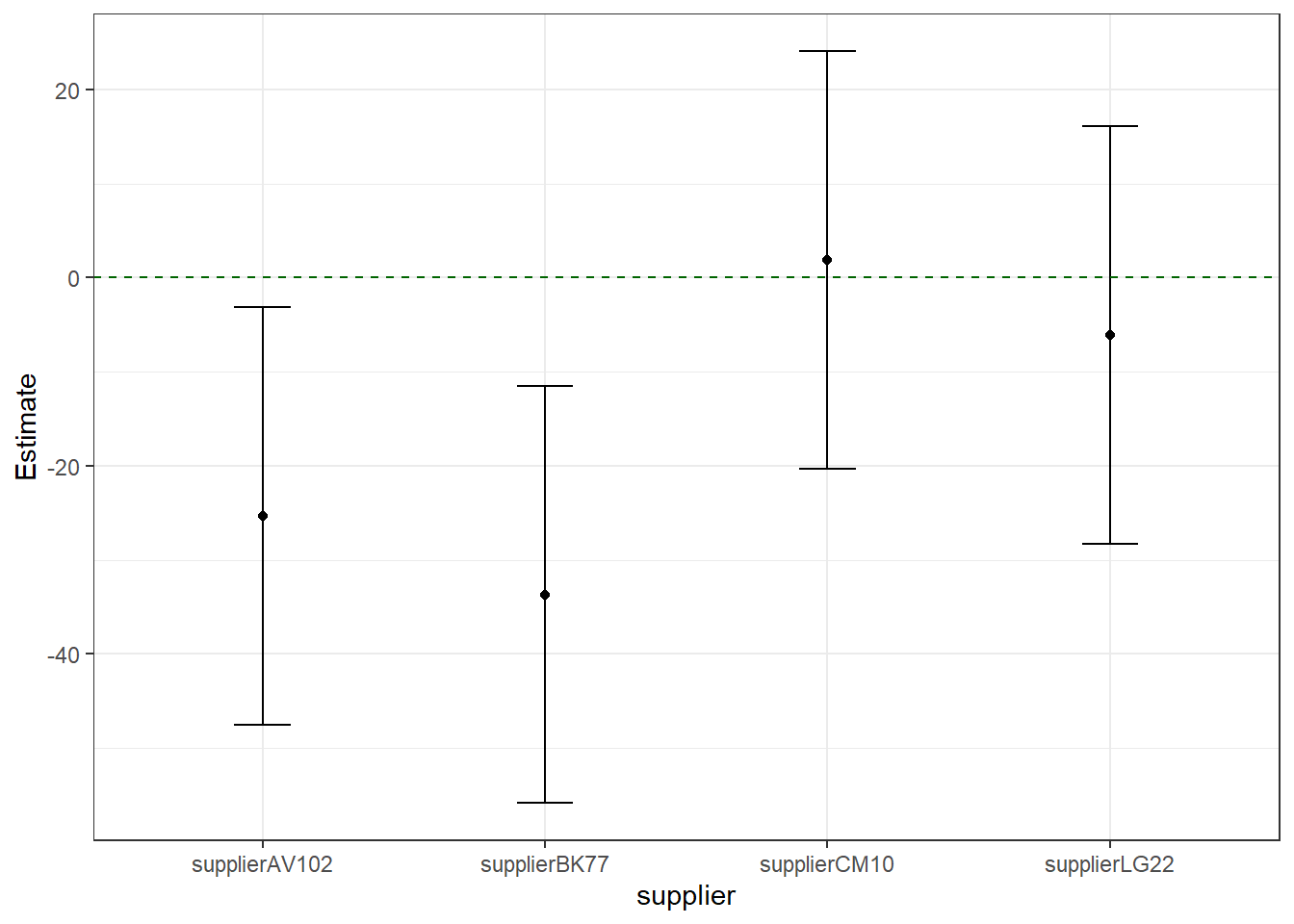
In the plot below the estimates of the differences of the chicken weights of all alternative feeds compared to chickes fed with Our104 are provided. A line is drawn to indicate where the zero effect would be. Confidence intervals that include this line point at mineral mixes that are not significantly different from Our104.
This data set and model is an easy case because we have a very simple fixed effect structure: only one factor. For more complex fixed effects bootstrapping methods need to be used. We will explain this later in the later paragraph.
The end the story on the confint() function: it can also be used to calculate confidence intervals on the random effects, what can illustrate a how well the model fits and what the issue may be with the data set.
Here we notice the random effect cage could be anything between zero (so all cages behave the same, to and important difference.). This could be caused by the limited number of cages or birds in a cage.
2.2 Bootstrapping for calculating confidence intervals
As said, the confint() function is restricted to confidence intervals of model coefficients already present in the model definition. A wider applicable method is bootstrapping, which we could apply for instance when we would be interested in contrasts of two new feeds, or even funkier things like proportions of something.
Bootstrapping is a general applicable procedure. Bootstrap estimates are obtained by repeatedly refitting the model on resamplings of the data with the same size and structure of the original data and extracting the parameter of interest. The distribution of these samples is a good approximation of parameter estimate uncertainty, from which confidence intervals can be derived.
Bootstrapping is a generic methodology not specifically related to mixed models. If you are interested, you will find elsewhere good introductions to bootstrapping.
To run this for lmer models the special function bootMer() has been developed. You have to supply the extractor function (in code below called bootfun), ideally a function that returns a vector, and apply this on the model via bootMer. The output in a matrix of whatever is the output of the extractor function in the columns and each bootstrap sample in a row.
As an example, say we need to know how large the difference is between BK77 and CM10.
A first thing you could check is the estimate of the difference. To do this you ask for the predictions (predict()) for each and subtract one from the other.
The argument newdata is a data that contains the effects in the model with the levels we need (in this case supplier with levels BK77 and CM10). Ignore the argument re.form for the time being. It will be explained later in more detail, but relates to how the random effects enter in the prediction. In this case it is set to NA and therefore cage is not needed in the newdata data frame.
This function is now supplied to the bootMer function and we ask for 1000 bootstrap samples (we do more to get a stable results for more complex models)
bs <-bootMer(modlmer.1.0,bootfun,nsim=1000)# to see the first 20 bootstrapped estimates of the differencehead(bs$t, 20)
# compared to confint(modlmer.1.0,parm="supplierBK77")
Computing profile confidence intervals ...
2.5 % 97.5 %
supplierBK77 -55.85702 -11.50548
Except that we realize that the contrast should have been the other way round (wrong sign…), the results are not identical. There is of course some stochasticity in the bootstrap, but the main reason we get a narrower interval lays elsewhere. We come back to this in the next chapter.
2.3 On the side: convergence issues
One of the issues with more complex data sets and more complex algorithms to solve them, is that algorithms may not converge.
Often one is too ambitious (so collect more data or make you model simpler), but sometimes a slower but more robust algorithm may get you further. For the models run by starting mixed-modellers, speed is seldom an issue. A switch to a more robust algorithm can avoid a lot of convergence problems. (or switch to Bayesian methods, see further).
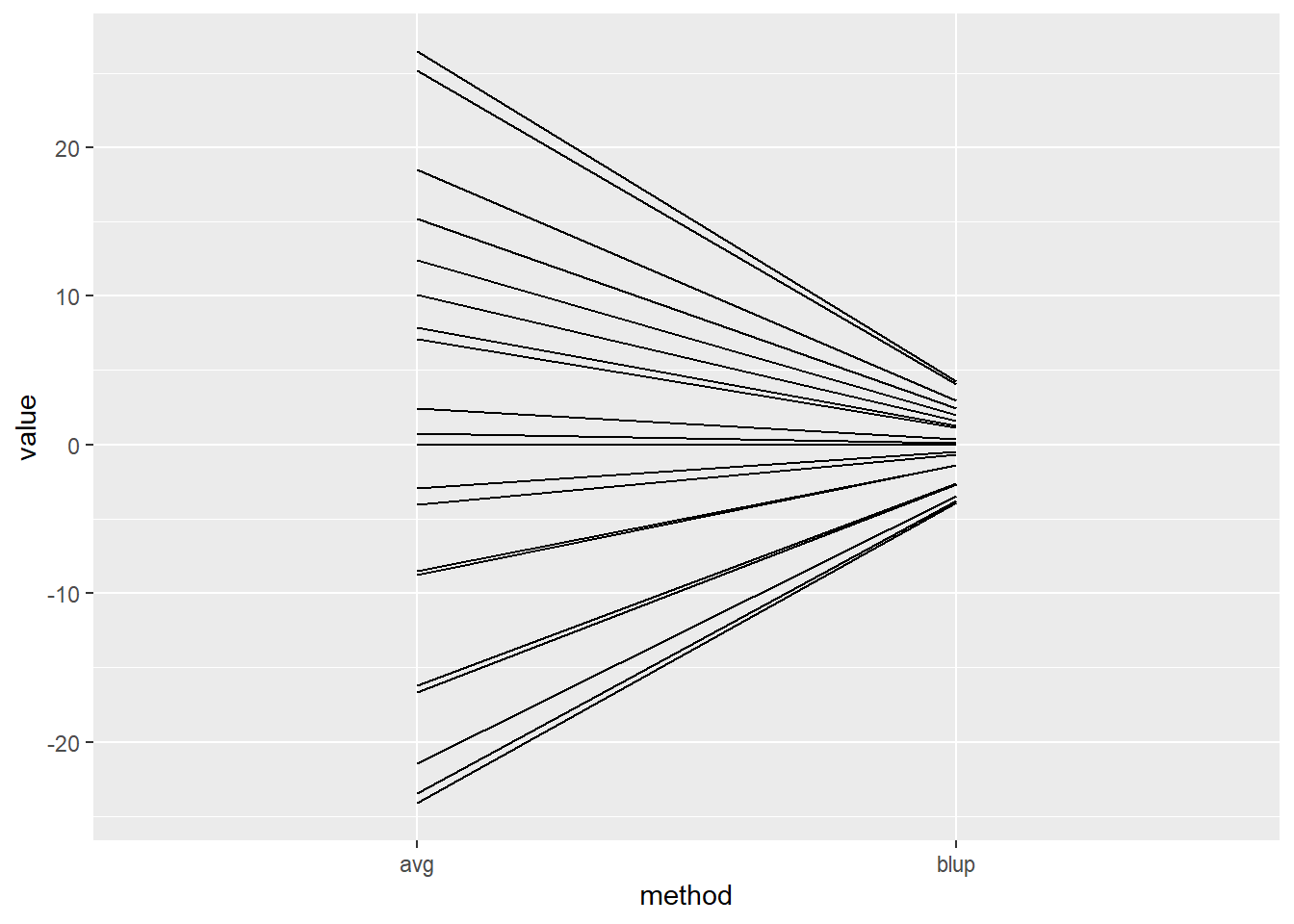
Sometimes the units that form the grouping are of interest. In this specific case the cages may not be our primary focus of attention, but sometimes it could be. In the frame work of mixed models evaluations of those groups are a combination of the actual observations within those groups and the fact they belong to a distribution described by all other groups in the data set. So for each cage we have a prediction rather than the pure estimate (i.e only corrected for the fixed effect of supplier) In the case of mixed models these are called a blup (best unbiased prediction).
These blups are shrunken compared to the estimates as can be seen in the graph below that compares the raw means of the cages with their blups. This shrinkage is the result of the combination of the data of the specific cage and the fact that is should fit within the framework of hierarchies and the behaviour within the other cages.